我的家鄉(xiāng)滄州——網(wǎng)頁(yè)與網(wǎng)站設(shè)計(jì)課程設(shè)計(jì)方案
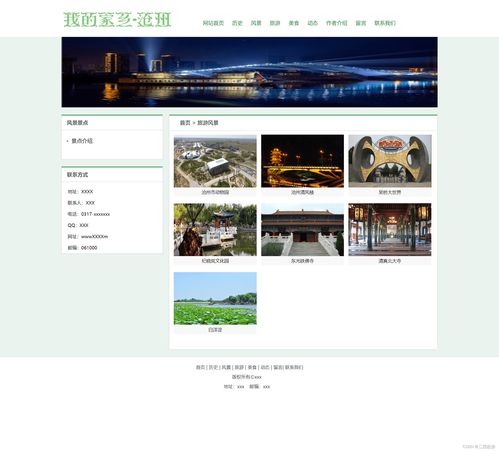
本課程設(shè)計(jì)以我的家鄉(xiāng)滄州為主題,使用HTML和CSS技術(shù)構(gòu)建一個(gè)六頁(yè)靜態(tài)網(wǎng)站。該設(shè)計(jì)方案結(jié)合網(wǎng)頁(yè)規(guī)劃、視覺設(shè)計(jì)與技術(shù)實(shí)現(xiàn),滿足課程設(shè)計(jì)的基本要求,并附帶詳細(xì)的報(bào)告說(shuō)明。
一、網(wǎng)站整體規(guī)劃
- 網(wǎng)站主題:我的家鄉(xiāng)滄州
- 頁(yè)面數(shù)量:6頁(yè)
- 首頁(yè):介紹滄州整體概況
- 歷史文化頁(yè):展示滄州歷史沿革與文化遺產(chǎn)
- 名勝古跡頁(yè):介紹滄州著名景點(diǎn)
- 特色美食頁(yè):展示滄州傳統(tǒng)美食
- 經(jīng)濟(jì)發(fā)展頁(yè):呈現(xiàn)滄州產(chǎn)業(yè)特色
- 聯(lián)系我們頁(yè):提供反饋與聯(lián)系方式
二、技術(shù)實(shí)現(xiàn)方案
- 開發(fā)語(yǔ)言:HTML5 + CSS3
- 布局方式:采用響應(yīng)式布局,確保在不同設(shè)備上的顯示效果
- 樣式設(shè)計(jì):使用外部CSS文件統(tǒng)一管理樣式,保持網(wǎng)站風(fēng)格一致
- 交互效果:通過(guò)CSS動(dòng)畫和過(guò)渡效果增強(qiáng)用戶體驗(yàn)
三、網(wǎng)頁(yè)設(shè)計(jì)特色
- 色彩搭配:以藍(lán)色為主色調(diào),體現(xiàn)滄州濱海特色
- 導(dǎo)航設(shè)計(jì):固定頂部導(dǎo)航欄,便于用戶快速切換頁(yè)面
- 內(nèi)容展示:圖文并茂,合理使用網(wǎng)格布局和卡片式設(shè)計(jì)
- 視覺效果:適當(dāng)運(yùn)用陰影、圓角等現(xiàn)代設(shè)計(jì)元素
四、網(wǎng)站結(jié)構(gòu)與功能
- 首頁(yè):包含城市簡(jiǎn)介、特色亮點(diǎn)輪播圖
- 歷史文化頁(yè):時(shí)間軸展示歷史沿革,圖文介紹文化遺產(chǎn)
- 名勝古跡頁(yè):分類展示滄州鐵獅子、吳橋雜技大世界等景點(diǎn)
- 特色美食頁(yè):網(wǎng)格布局展示滄州火鍋雞、羊腸湯等美食
- 經(jīng)濟(jì)發(fā)展頁(yè):數(shù)據(jù)可視化展示滄州經(jīng)濟(jì)發(fā)展成就
- 聯(lián)系我們頁(yè):包含留言表單和地圖定位
五、課程設(shè)計(jì)報(bào)告內(nèi)容
- 項(xiàng)目背景與目標(biāo)
- 需求分析
- 網(wǎng)站規(guī)劃與設(shè)計(jì)思路
- 技術(shù)實(shí)現(xiàn)細(xì)節(jié)
- 遇到的問(wèn)題與解決方案
- 項(xiàng)目總結(jié)與收獲
六、預(yù)期效果
通過(guò)本課程設(shè)計(jì),學(xué)生能夠掌握網(wǎng)站規(guī)劃與設(shè)計(jì)的基本流程,熟練運(yùn)用HTML和CSS實(shí)現(xiàn)靜態(tài)網(wǎng)站開發(fā),同時(shí)加深對(duì)家鄉(xiāng)文化的了解,提升綜合設(shè)計(jì)與實(shí)現(xiàn)能力。
該項(xiàng)目不僅滿足課程考核要求,更是一個(gè)展示家鄉(xiāng)文化、提升專業(yè)技能的良好平臺(tái)。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.mbroom.cn/product/44.html
更新時(shí)間:2026-03-13 11:42:39